A Grammar for Reproducible and Painless Extract-Transform-Load Operations on Medium Data

Benjamin S. Baumer https://bit.ly/2LzLZtm Joint Statistical Meetings July 31st, 2018
Ben Baumer
Benjamin S. Baumer https://bit.ly/2LzLZtm Joint Statistical Meetings July 31st, 2018





| “Size” | size | hardware | software |
|---|---|---|---|
| small | < several GB | RAM | R |
| medium | several GB – a few TB | hard disk | SQL |
| big | many TB or more | cluster | Spark? |
etletl_extract()etl_transform()etl_load()
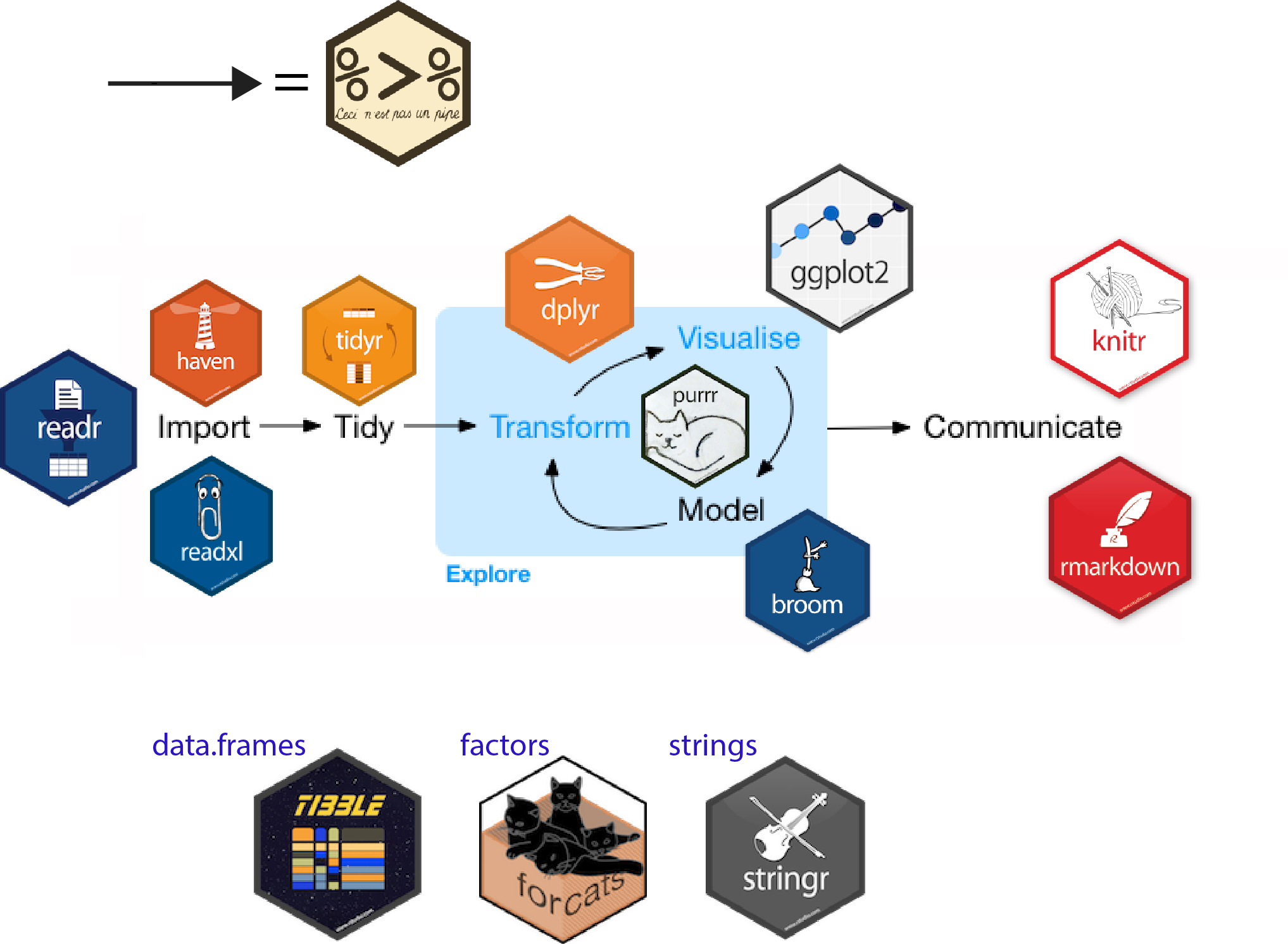
etletl vignettecreate_etl_package()default methodsetl_extract.foo()etl_transform.foo()etl_load.foo()
dplyr and rstats-db developers!!







