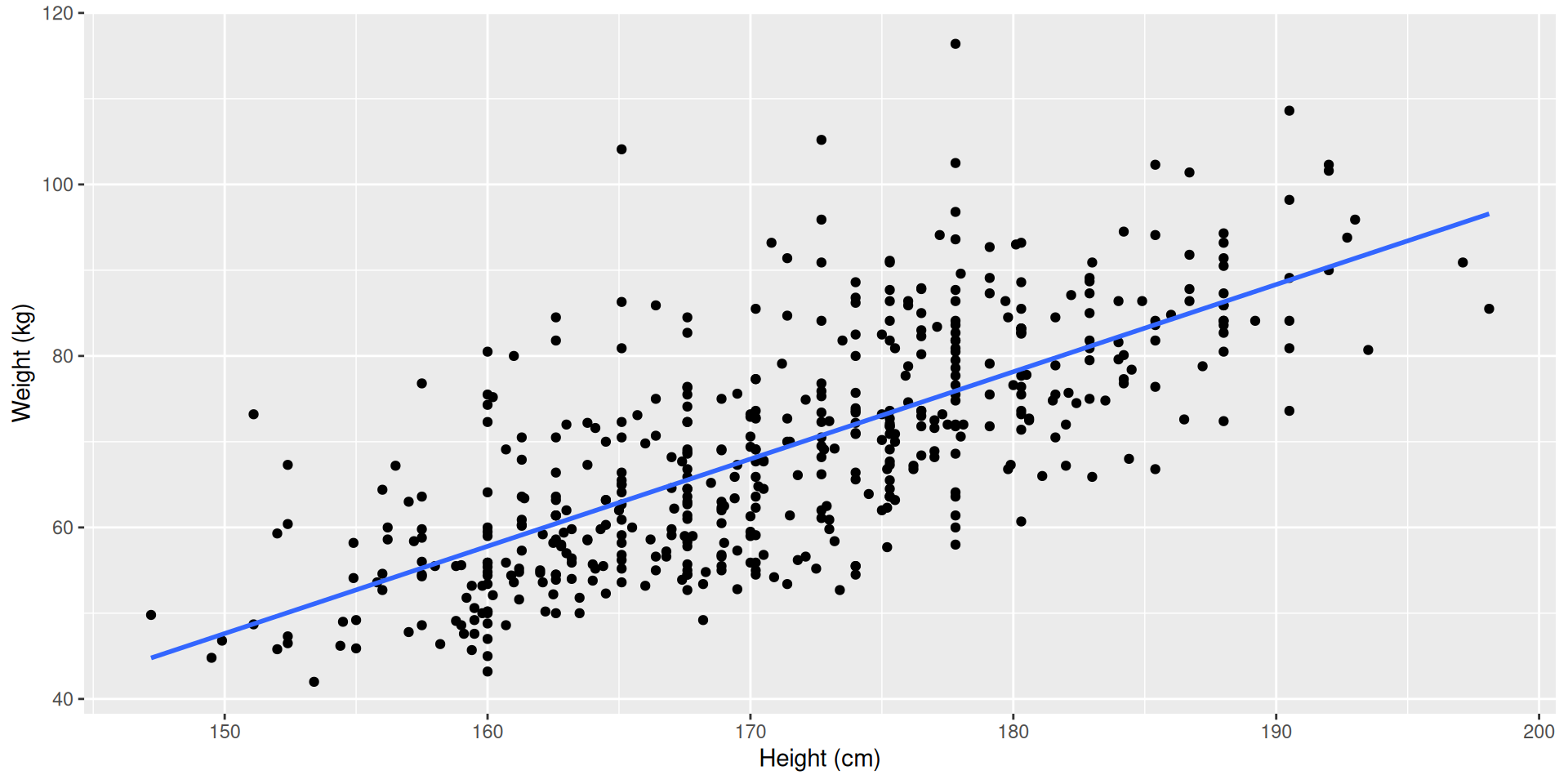
Body dimensions
Consider the relationship between weight (kilograms) and height (centimeters) of 507 physically active individuals.
library(tidyverse)
library(openintro)
data_space <- ggplot(bdims, aes(x = hgt, y = wgt)) +
geom_point() +
geom_smooth(method = "lm", se = 0) +
scale_x_continuous("Height (cm)") +
scale_y_continuous("Weight (kg)")