136 BVectors
Mini-Lecture 2
Ben Baumer
Smith College
2024-09-05
Slack review
Garbage collection
when does R determine that a file is no longer needed to be considered for garbage collection?
- Garbage collection is lazy
- Your OS reclaims memory from R only when it needs it
Tibbles
I can’t seem to figure out why there is such a difference in the memory usage of a tibble vs a dataframe? Is it because a dataframe is more like a proper file where as a tibble is like preview?
Wide vs. long
I understand why “long” and “wide” data would take up different amounts of memory in Exercise 7 but am curious why long format data takes up more? Intuitively I would have thought that fewer vectors would take up less space than more vectors, even if they’re longer
- There is overhead because
pivot_longer()adds a new variable
Wide vs. long (cont’d)
- But you’re right otherwise (about factors, at least)!
When does it matter?
When does object size start to make a noticeable difference in the efficiency/speed of the code? For example, if you had a long data frame vs. a wide one, is there a # of rows/columns that would make long tables slow your code down significantly with a long frame instead of a wide one, or is it just completely dependent on what kind of program you’re running?
- Sounds like a great project!
Vectors
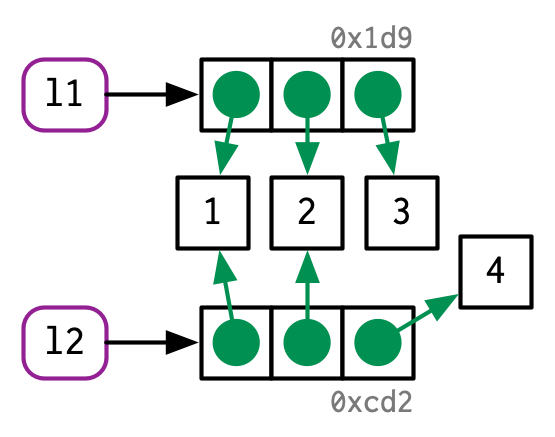
Clarification
- Lists always store references to other objects
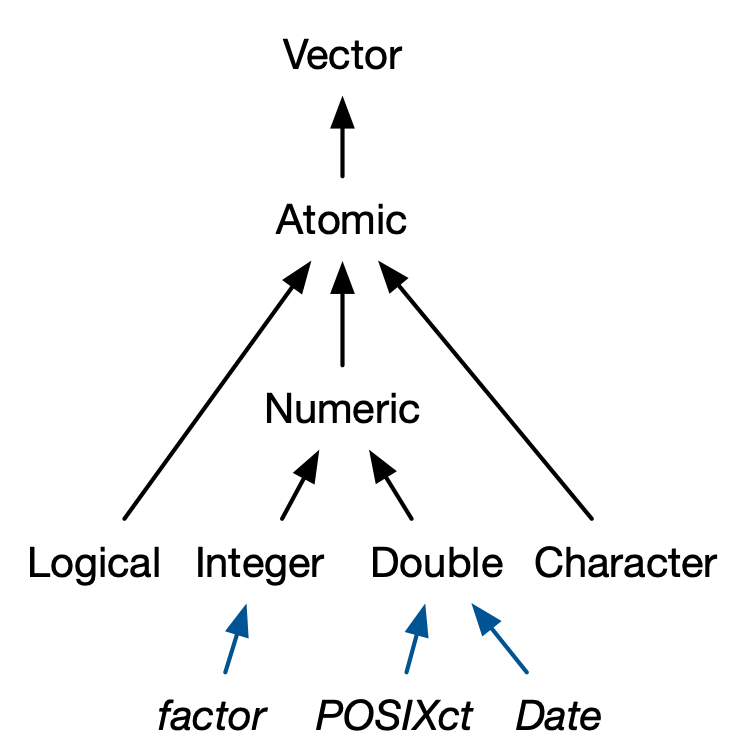
Coercion
character → double → integer → logical
- Makes more sense to me that the arrows go the other way!
data.frames and tibbles
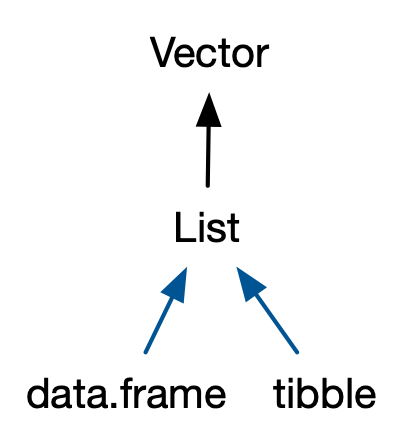
Differences
tibble()never coerces an inputtibble()won’t transform non-syntactic namestibble()only recycles vectors of length 1tibble()allows references to created variables[always returns a tibble$doesn’t do partial matching
Method-oriented programming?
- Suppose we have an
instrumentobject calledviolinand a method calledplay()
- but in R:
List-columns
- Where have you seen this before?
sfobjects havegeometrylist-column- fitting many models
sf list-columns
# A tibble: 1 × 2
area geometry
[acre] <POLYGON [°]>
1 255. ((-72.68133 42.45536, -72.68108 42.45539, -72.68111 42.45549, -72.6811…[1] "sfc_POLYGON" "sfc" [1] "list"nest() and unnest()
Now
Work on
Lab #2: Vectors
Reading quiz on Moodle by Sunday night at 11:59 pm
![]()
SDS 410