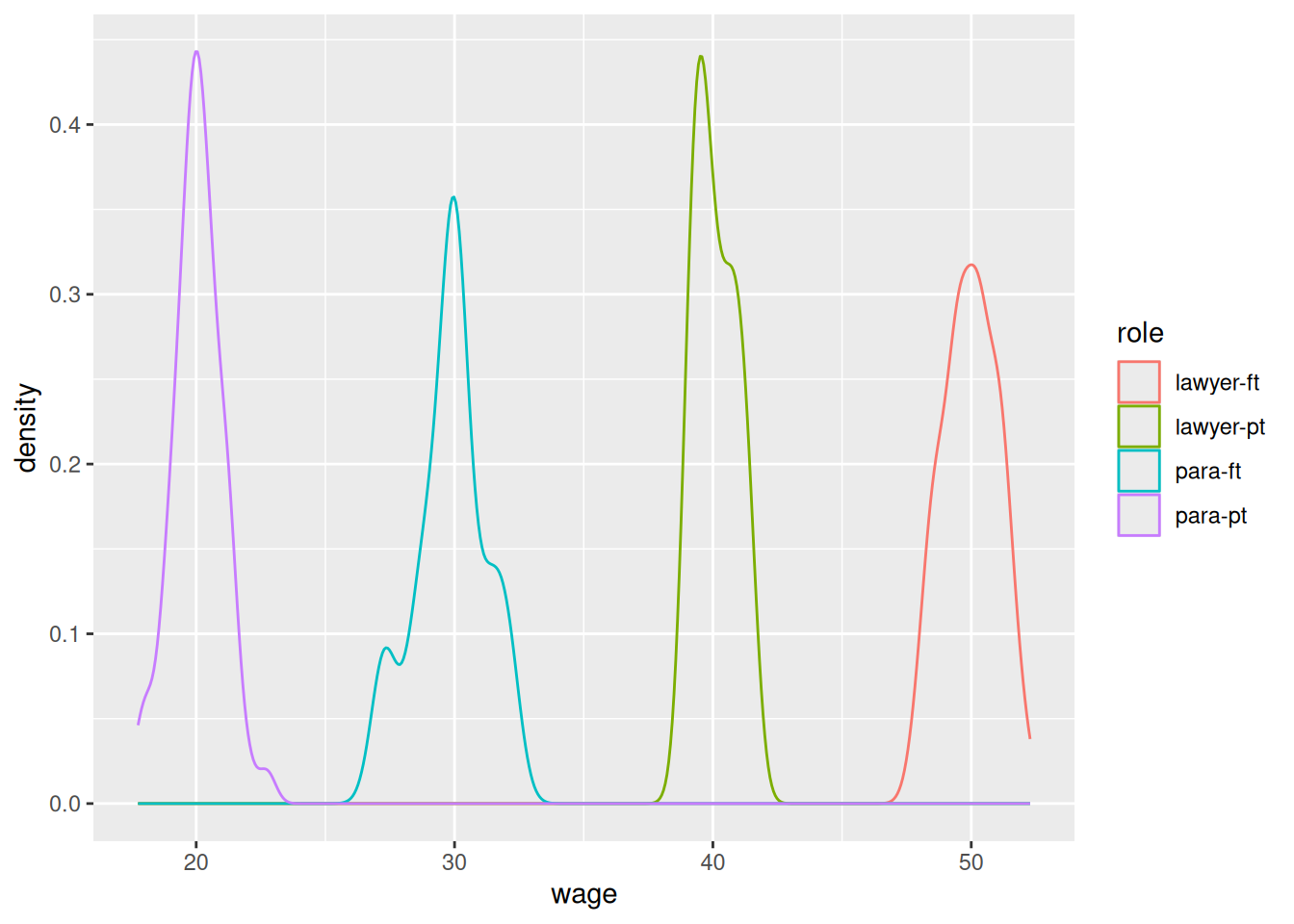
Recall the stratified sampling exercise from last time, and suppose that hourly wages were normally distributed with means $50, $40, $30, and $20, among the 90 lawyers working full-time, 18 lawyers working part-time, 9 paralegals working full-time, and 63 paralegals working part-time, respectively. The following R code builds a data frame that represents one possible reality.
Note that wages are similar within the four groups, but dissimilar among the groups. This command will draw separate densities for the four groups on the same plot.
ggplot(data = staff, aes(x = wage, color = role)) +geom_density()
We want to estimate the mean wage among all 180 workers. In this case, since we know the wage of all of the workers, we can just compute it.
actual <- staff |>summarize(number_of_employees =n(),mean_wage =mean(wage) )actual
Note that this is close to the actual mean wage, but not the same. Note also that each time we take a different random sample, we get a different mean wage in that sample.
Stratified sampling
Now let’s implement the stratified sampling scheme.
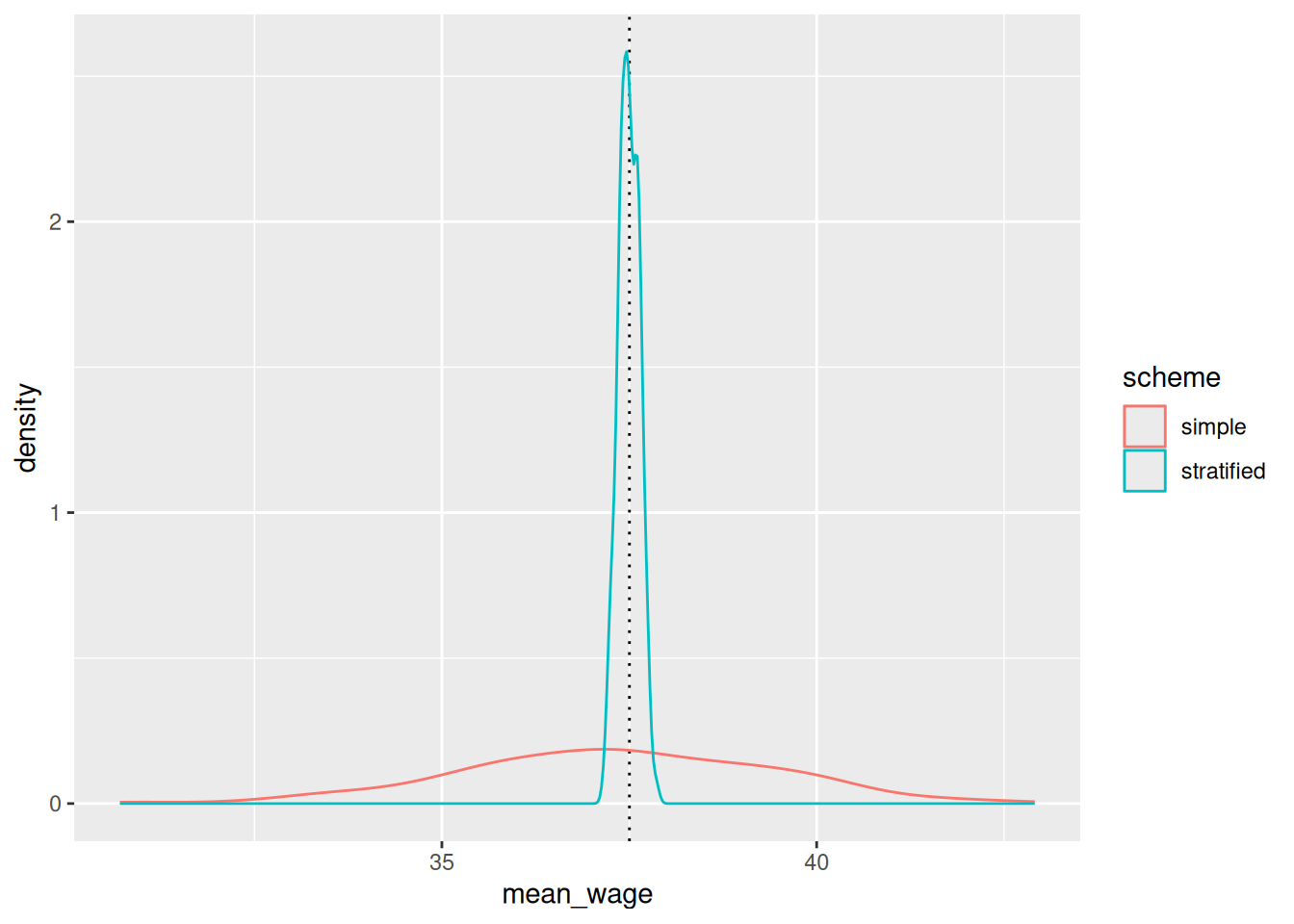
Again, the stratified sample mean is close to the actual value, but not the same. It will also differ each time we take a different random sample. So why might we prefer stratified sampling over simple random sampling?
Sampling distributions
Let’s compare the distribution of sample means if we do this many, many times!